

deel dit bericht op


Prompt Engineering Best Practices
Building Reliable LLM Systems With Evaluation Frameworks
08 October, 2025
Every few months, someone proclaims that prompt engineering is dead. But since LLM-based systems are fundamentally governed by prompts, it’s unlikely to disappear anytime soon. Newer models may be better at interpreting our instructions, but even human teammates need well-structured briefs and contextual information to handle complex tasks. Writing a good brief takes skill, whether you’re working with people or prompting LLMs - but AI systems require a different methodology.
While sound prompt engineering should form the critical foundation of any reliable LLM-based system, many organisations find themselves trapped in an endless cycle of prompt iterations, hoping for better results through trial and error, without measurable indicators of progress. It feels like playing a complex board game where someone forgot to include the rulebook: you're making moves, but you can't tell if you're actually winning or just moving pieces around.
True confidence in your LLM system doesn’t come from intuition. It comes from methodically crafted prompts and robust evaluation systems. This combination helps you identify how to improve prompts when results fall short, and reveals whether your latest prompt is actually driving better outcomes - or just feels different without a real quality gain.
This post explores the key building blocks of a solid system prompt and highlights how we resolved several costly errors during the prompt design process for a live project at Supercharge.
If you’re a product manager, AI expert, or anyone responsible for shaping LLM-driven products, this post will help you avoid the trap of endless prompt tweaking and instead build confidence through solid system design and evaluation.
System Prompts in LLMs: Exceeds How You Prompt ChatGPT
At its core, prompting defines how your Agentic AI system behaves and responds, acting as the foundational instruction set that guides its output.
An ideal prompt is clear, dense, and easy to understand, leaving no room for misinterpretation.
In ChatGPT (or any other personal LLM), the prompt is typically a single user message. But in complex AI systems prompts are often enriched with additional components - such as context, explanations, or relevant documentation - to guide the model more effectively.
It’s essential to acknowledge that LLMs lack genuine awareness or understanding of the tasks they’re assigned. They mimic human responses without truly grasping the underlying purpose of what they’re doing. This makes them poor at filling in the gaps in case of obscure requirements.
Proper prompting that mitigates this shortcoming can have a significant impact on the quality of the LLM response, as often small changes in wording or structure can produce dramatically different results.
Example Project: AI Augmented Support Drill Testing
At Supercharge, our technical support team handles critical live incidents that require strict adherence to established protocols based on a knowledge base of procedures. An accurate response can mean the difference between swift resolution and costly escalation.
To keep our support agents sharp and ensure they follow protocol, we built an automated training system that runs regular, realistic drills. These drills are evaluated by a large language model (LLM), which checks each agent’s response against our internal procedures. This means agents get a consistent, unbiased assessment without needing team leads to review every case.
The system isn’t just for assessment, as it provides instant feedback, helping team members identify and address any knowledge gaps. It enables us to continuously test and improve our readiness, ensuring the team is prepared for real client incidents.
The examples we use in this article are taken from the prompt we designed for this LLM-based system.
3 things your prompt should contain
Effective prompts may appear as simple, continuous text, but behind the scenes, they’re made up of several logical building blocks that each serve a specific purpose:
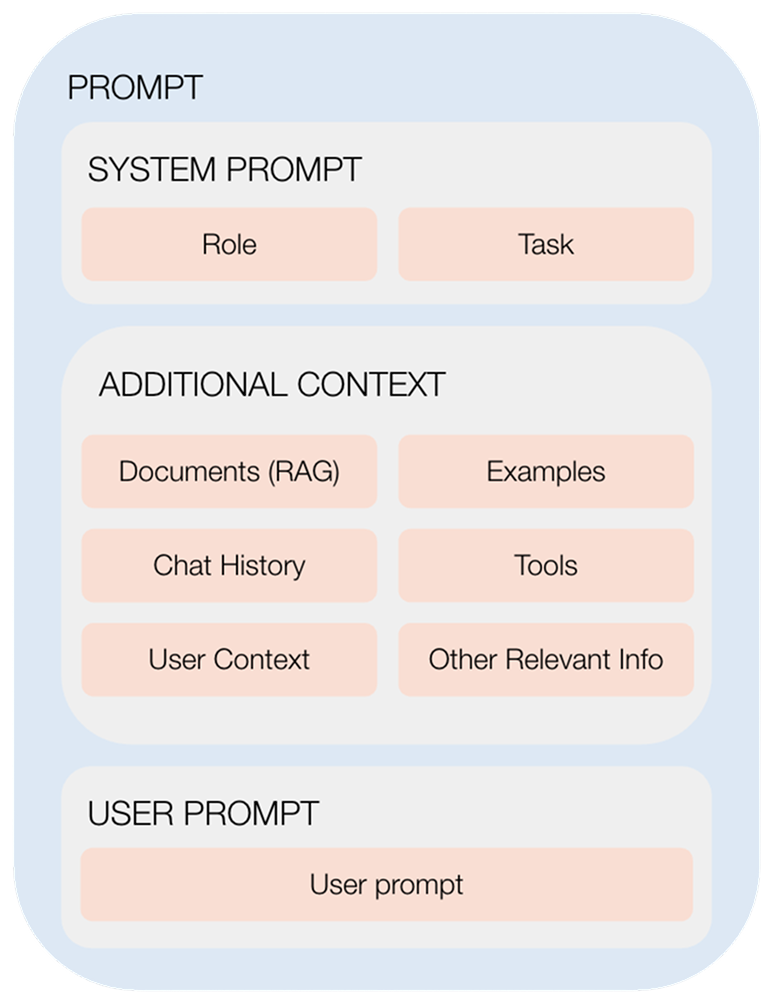
1. System prompt
The system prompt defines the AI’s core role by outlining the task it should perform and the behavioural standards it should follow.
The role defines the LLM's intended function through clear, direct statements that describe its persona and behavioural traits.
For example:

Instructions describe the guidelines, rules and protocols the agent should follow during task completion as strictly as possible. These instructions should also specify the expected output format and structural requirements.

2. Additional context
The additional context section provides supplementary information that enhances the LLM’s understanding of the specific task. This context helps overcome the model's knowledge limitations by supplying current, accurate, and task-specific information.
This may include retrieved documents (via RAG), available tools and functions, user background information, conversation history, example solutions to similar problems, and other relevant data sources.
3. User prompt
In systems that interact with users through text interfaces, the prompt also includes the user’s input - what you type when chatting with an AI System like ChatGPT. In other setups, this input may come from different IT systems rather than a person. Whether it’s a question, a request for analysis, or task-specific instructions, this input helps the AI understand what needs to be done. It becomes part of the overall context, alongside the other building blocks described above.

To learn more about creating effective user prompts, check out our previous article, which covers some of these concepts [1].
Example System Prompt
This example is simplified for the sake of clarity:
|
You are an expert trainer who is responsible for evaluating support agent responses during practice drills. [...] Scoring:
Drill: <Task> Knowledge Base Content: Answer by support agent: <Answer> Respond ONLY with a JSON object in this exact format: {{"name": "AI Evaluation", "value": 4, "summary": "Your detailed feedback here"}}` |
System Prompting Pitfalls
Lvl 1: Anything that can be misunderstood will be misunderstood
Murphy’s Law applies to LLMs too: anything that can be misunderstood will be misunderstood, right down to details that humans would consider trivial.
Let's look at two examples from the project where we utilised an LLM to assess our support team's responses to training drills. Below is a snippet of the prompt.

Observed symptoms:
1. Evaluation scores were inconsistent, seemingly random, and unrelated to the actual content of the answers.
2. No team member scored higher than 4, not even when giving the perfect target answer.
Based on the prompt snippet, what would you think is the root cause of the observed symptom?
Underlying issues:
1. The prompt was inconsistent with its own terminology. We instructed the model to 'score' responses, but our example output used the field name 'value' instead of 'score.'

2. The model fixated on our example output. Since we used a score of 4 in the demonstration, it began defaulting to that same score regardless of the answer’s quality.

The revised prompt:

As we said, what can be misunderstood will be misunderstood by the AI. Prompt phrasing must be extra direct and consistent throughout.
Lvl 9999: How to handle more intricate cases?
Sometimes, no amount of prompt iteration resolves persistent, spooky evaluation issues. These are especially challenging to pinpoint when they originate from the Retrieval Augmented Generation (RAG) component, where the underlying issue often lies in the document corpus.
These retrieval issues typically fall into four categories:
1. Insufficient coverage - Key information is missing from the document collection.
2. Poor ranking - Relevant documents exist but aren't being retrieved. For example, having too much overlap in the covered information across documents messes up the similarity scoring mechanism.
3. Conflicting information - Retrieved documents contain contradictions or inconsistencies.
4. Wrong context - The retrieval system finds documents that seem relevant but don't actually address the query
We faced this problem ourselves and realised it stemmed from issues in the internal document set powering our RAG-based knowledge base.
Let’s look at a snippet from retrieved documents in our project where we used an LLM to evaluate our support team's responses to training drills:

Observed symptoms:
- While the AI scoring met expectations in the majority of drills, it continued to produce inconsistent results in a few specific cases and edge scenarios.
Based on the prompt snippet, can you spot the root cause of the observed symptom?
Underlying issues and how to fix them:
- A contradiction in our knowledge base created an unresolvable evaluation scenario. When the RAG system retrieved both relevant but conflicting documents, the AI evaluator lacked a consistent ground truth, resulting in inconsistent scoring depending on which policy it assigned more weight to.
The revised documents:

Even with thorough reviews, large knowledge bases often contain inconsistencies, unclear wording, or outdated content. While evaluating this project, we identified several instances of obsolete or inaccurate information that had previously escaped our audits. These only came to light when they confused the AI system.
Once again, what can be misunderstood by humans will definitely be misunderstood by AI, and inconsistent source material amplifies this problem exponentially. As a fortunate side effect of debugging this RAG issue, our overall knowledge base quality improved significantly.
Through our work on prompt engineering in this project, we identified several critical lessons:
1. LLMs miss trivial details that humans grasp intuitively
2. Direct, consistent phrasing is essential - even minor terminology shifts create confusion
3. Examples can anchor model behavior more than we expect
4. Document quality matters, as RAG issues often stem from flawed source material we assumed was reliable
LLM evaluation frameworks: measuring progress for real confidence
Prompting is often referred to as an art rather than a science. But you can't rely on arts and intuition alone for high-stakes projects. The key to putting the engineering into prompt engineering - and turning it into a systematic, controlled, evidence-based, scientific process - is to establish best practices and apply rigorous performance measurement.
As the saying goes, if you can’t measure it, you can’t improve it. That’s why creating a robust evaluation framework is essential. Evaluation provides a structured way to measure how well your AI performs against defined criteria such as accuracy, consistency, and alignment with expectations. It allows you to assess the system’s quality, trustworthiness, and robustness, compare different versions, and ultimately build greater confidence in its reliability.
The Path Forward: From Art to Science
Most organisations still treat prompt engineering as a trial-and-error process, but serious business applications require reliability, measurability, and continuous improvement. The good news is that we already have the tools to make prompt development far more systematic and controlled.
It starts with the basics: writing prompts that are overly clear, overly specific, and overly consistent. You don’t need to worry about sounding too pedantic to an AI system. Write prompts that don't leave room for misinterpretation.
LLMs work best when instructions are unambiguous, so we structure our prompts accordingly. But here’s where it gets tricky: improving one part of a prompt can unexpectedly affect performance in other areas.
And that’s precisely when a solid evaluation framework starts to matter. Instead of just fixing one issue at a time, like improving how the AI handles tone or follows specific instructions, we track multiple metrics simultaneously.
This is important for you to see the full picture of how the system performs across all the dimensions that matter to your use case. Otherwise, you might be solving one problem while creating others. For example, if you adjust a prompt to make the AI more concise, it might accidentally lose important details or become less accurate. A good evaluation framework helps you spot those trade-offs.
This approach takes more upfront work, but it pays off in reliable, consistent results. That’s what separates successful AI implementations from experiments that never make it to production. What you can’t measure, you can’t optimise - and in the end, you can’t trust.
Sources
1. Understanding how LLMs think https://supercharge.io/blog/how-large-language-models-work-cases-risks-responsible-ai
FAQ
Let's think about your own AI-enabled product together!
The form is loading...


