

deel dit bericht op


How Data Chaos Kills Your Agentic AI Initiatives
21 October, 2025
Just as the business world was starting to wrap its head around how AI models are trained, the world moved on. The old paradigm, in a nutshell, was this: take high-quality data, set up a model, and let it learn patterns to make useful predictions in its narrow domain. Recognise a person in a photo. Forecast tomorrow’s energy demand, despite all the complexity of influencing factors. And just when it became obvious that company-specific data on strategic factors is what really drives results, Generative AI burst onto the scene, confusing most people all over again.
Generative AI has transformed AI from being a useful but expensive and data-hungry technology, mostly reserved for the largest enterprises and tech giants with access to vast amounts of big data, to something far more widely accessible. Until recently, only those with the scale to justify heavy investments in training narrow, use-case-specific AI could truly benefit. With GenAI, that has changed.
More specifically, Agentic AI powered by reasoning Generative Models (Large Language Models) has brought us much closer to the original dream that has driven AI research for over 70 years: machines that can think like humans and solve problems with increasingly general intelligence. We can now automate complex processes that require dynamic understanding and decision-making, and we can equip AI with tools to perform real, valuable tasks, whether to support human work or, in some cases, to replace it.
LLMs seemingly arrive pre-trained and ready to go. With the right prompting, they can take care of all sorts of useful things. So you don’t need data or data engineering anymore to make them work, right?
Dead wrong. You need them more than ever. We didn’t leave data behind; we just moved from big data to smart data.
Read on to see why high-quality, well-structured data is still the key to delivering real impact with this new flavour of AI.
From General Models to Master Problem-Solvers for Your Specific Challenges
People often assume that new Generative AI models can solve problems straight out of the box. But ambitious companies are not just looking to hand their teams a ChatGPT- or Copilot-style generalist tool. They want to build Agentic AI systems that can fundamentally transform and amplify their specific business processes.
As we move from generalist tasks toward complex, company-specific workflows, some level of customisation or fine-tuning becomes essential. The reason is simple. LLMs are not narrow AI models. They are general-purpose systems trained on massive volumes of publicly available data, covering almost everything, but optimised for nothing in particular.
Even as AI labs fine-tune models using Reinforcement Learning for specialised tasks like coding or maths, that work rarely aligns with the unique needs of your business. To make an AI model truly effective inside a company, it must be exposed to that company’s own data, context, and challenges. And that hinges on high-quality, reliable data. But how do Agentic AI systems leverage data?
The AI Agents That Live in the Digital Twin of Your Business
The premise of Agentic AI is simple. Large Language Models act as “brains,” using semantic reasoning to understand inputs, create plans, and execute tasks. They are called agentic because they can make decisions and take action with a degree of autonomy.
While putting these models into physical robots may sound promising (or frightening), the systems businesses are deploying today are digital minds running inside their existing IT environments. Besides user and system instructions, their inputs and outputs are all types of data - from spreadsheets and databases to documents and emails.
When we provide AI agents with tools (such as access to APIs through MCP servers), we are primarily giving them access to data sources, ranging from Google search results to transaction data from a core banking system.
Through the eyes of a data professional, companies can be seen as data factories. Every invoice, transaction, or internal workflow captured by back-office systems generates dozens of data points.
We don’t usually think of our organisation’s data and systems — the files, spreadsheets, business rules, and logic spread across SaaS platforms and ERP environments — as a digital twin of our company. But increasingly, that’s exactly what they are.
If we want AI agents to create real value, they need to be able to navigate and operate within this abstract version of reality.
An Orderly Workplace is an Effective Workplace (also for an AI Agent)
If all the data relevant to a task is well-structured, easy to find, and easy to interpret, Agentic AI systems can operate effectively and reliably. But when the data is messy, fragmented, or locked away in silos, their performance drops quickly - or they fail entirely.
Most companies still struggle with unstructured formats, disconnected systems, and incomplete records. Giving an Agentic AI system access to a chaotic data landscape leads to unreliable insights, hallucinations, or flawed automation. Let’s take hallucination, the often-cited Achilles’ heel of Generative AI systems. In practice, it most often occurs when the model tries to produce a useful output but lacks access to relevant data. The fact that the data exists doesn’t help much if it can’t be located or is too difficult to work with.
Being “AI-ready” is not just about having large volumes of data. It requires structured pipelines, standardisation, and strong data governance to ensure the information fed into these systems is accurate, consistent, and trustworthy.
Most companies have mountains of data scattered across the organization - in CRM systems, ERPs, cloud storage, and even thousands of individual PDF documents and spreadsheets. This is a potential goldmine, but in its raw state, it's more of a liability than an asset for an advanced AI system. The goal is to move from this scattered, indigestible state to a central, connected data repository - a single source of truth that various AI systems can draw upon reliably.
At the risk of anthropomorphising an AI system: who gets better results, the employee working in a well-organised library of facts, or the one stuck in a room where a whirlwind has scattered binders all over the floor?
Three Ways How Agentic AI Systems Leverage Your Data
We think simple frameworks that encapsulate fundamental truths about a technology are the most useful things for a business decision maker when they navigate the fast-changing landscape of Agentic AI. This simple framework helps you understand the three core ways how Agentic AI systems can use data - two of them are very frequent, the third is still rather rare.
1.) Direct access to databases
The simplest way to connect AI agents to your data is by giving them direct access to your existing databases and APIs - essentially handing them the same tools your traditional software uses. Through protocols like MCP (Model Context Protocol), an AI agent can query your CRM, pull from your data warehouse, or interact with your ERP system.
This works well for structured, straightforward queries. Need last quarter's sales figures? Customer contact details? Current inventory levels? The AI can pull these just like any application would. It's fast, real-time, and uses your existing infrastructure.
However, there's a limitation: these systems were designed for software that knows exactly what to ask, not for AI agents that must understand context. Your database might tell an AI agent that Customer #4851 has declined 30% in orders, but it won't explain that this customer mentioned switching suppliers in last week's call notes, or that they're undergoing a merger mentioned in their quarterly report.
What is an MCP Server that everyone talks about?
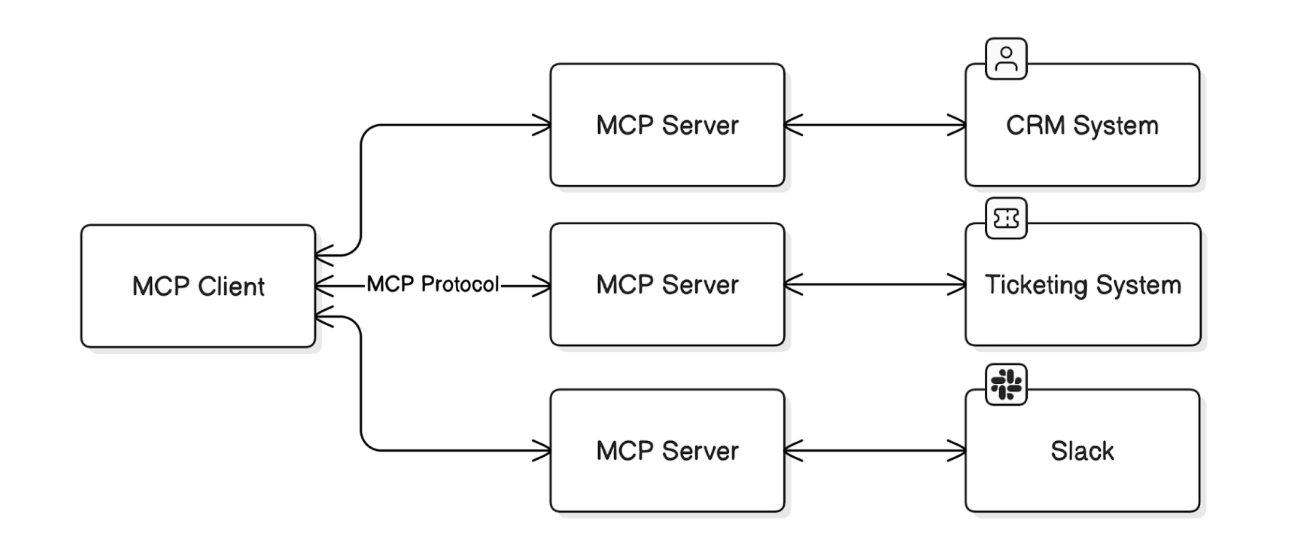
An MCP (Model Context Protocol) server is a purpose-built way for AI systems to use your tools and data. While a standard API might expose fixed endpoints like “get customer details,” an MCP server provides AI agents with a structured, machine-readable map of all available actions, along with guidance on how to use them safely. This allows the AI to explore what it can do with the tools the server exposes, which may include multiple APIs, understand when each action is appropriate, and chain them together to complete more complex tasks. For instance, an AI agent could extract a list of clients with low NPS scores from your CRM, correlate them with recent support tickets from your helpdesk tool, and identify customers at risk of churn, all by analysing the available actions exposed by the MCP server (or servers).
While you can enhance these connections with metadata and business rules, you quickly hit a wall: the most valuable context isn't in your structured databases at all. It's trapped in emails, documents, meeting notes, and reports scattered across your organisation. To access this rich, unstructured information and connect it with your structured data, you need a fundamentally different approach. That's where RAG and vector databases come in.
Use case: automated agent that runs at the end of each month to review financial reports
Let's consider an automated agent tasked with a monthly financial review. It connects directly to your ERP system's database to compare budgeted vs. actual project spending. The agent successfully identifies an anomaly for "Project Titan." Its output might look like this:
Alert: Project Titan actual spend: $1,350,000. Budgeted spend: $1,000,000. Variance: +35%.
This alert is factually correct but operationally useless. It tells you what the problem is, but not why. The agent has no way of knowing that the cause is a combination of supply chain delays documented in weekly progress reports and a price hike from a key supplier outlined in an email thread. To find the answer, a human analyst must still manually dig through unstructured documents, defeating the purpose of intelligent automation. This is the ceiling you hit with direct data access alone.
2.) The Backbone of AI Engineering: RAG and Vector Databases
Vector databases weren’t originally invented for LLMs, but the two technologies fit together like perfect puzzle pieces. In fact, most corporate Agentic AI use cases today are built around them.
LLMs learn patterns, not facts. Also once a given model version’s training is done, they don’t learn anything new. That means they’re not reliable sources of factual or up-to-date information. And if you, like almost everyone, are using a foundation model - like Claude, GPT or Gemini - it definitely wasn’t trained on your company’s specific data. This is where Retrieval-Augmented Generation (RAG) comes in. By combining LLMs with vector databases, RAG elegantly solves the problem: it gives the model fast, structured access to your internal knowledge, so it can answer questions accurately using your data, not just what it learned during training.
Think of a traditional database like a massive Excel sheet - useful, but only if you search using exact keywords. A vector database is different. It’s more like a hyper-intelligent librarian. You don’t need to know the exact title of the book you’re looking for. You can describe the idea or concept, and the librarian will return the most relevant passages across the entire library. That’s semantic search: data stored and retrieved based on meaning, not just matching words.
This enables a powerful process. RAG is one of those technical acronyms where the three words actually tell a coherent story. Here’s how Retrieval-Augmented Generation works in an automated workflow:
- Retrieve: Imagine an automated agent that runs at the end of each month to review financial reports. When it detects a significant cost overrun in a project’s budget, it doesn’t just flag the number. It immediately queries the vector database to retrieve all related information chunks: the original project proposal, supplier contracts, weekly progress reports, and internal communications that mention risks or delays.
- Augment: The AI system pulls these relevant information chunks and synthesises them to build a deeper understanding of the situation. It augments its thinking with real, contextual company data, not just what it learned during pretraining.
- Generate: Then the model generates its output, triggering a proactive alert for the finance department. For example: “Alert: Project Titan is 35% over budget. This correlates with a 3-week delay mentioned in the Q2 progress report and a 15% materials cost increase from Supplier B (link: see contract amendment 2.1). Recommend immediate review with the project lead.”
A vector database, continuously updated by well-structured data pipelines, can be a game-changer in building an intelligent organisation that is truly data-driven, without requiring employees to become data analysts. It enables the development of AI systems that function like tireless expert analysts, constantly scanning for issues, connecting dots across siloed data, and taking action based on their findings.
These AI agents do more than generate insights. They can deliver them directly into your workflow, whether that means sending a detailed alert to the project lead on Slack, creating a ticket in Jira, or automatically scheduling a project review meeting.
The example above shows just one RAG use case. RAG-based solutions also power everything from advanced chatbots to AI-enabled customer service systems. Vector databases, when utilised through RAG, are more purpose-built for Agentic AI systems than simply providing models with access to traditional data sources. The two paradigms can coexist and often work together, depending on the specific use case's needs.
3.) The Heavy Lifting: Fine-Tuning Language Models with Company-Specific Data
We left fine-tuning for the end, not because it isn’t important - in fact, it might be the next big direction for Agentic AI systems - but because it is still rarely used outside of AI labs.
Think of fine-tuning as sending a generalist AI model to a specialist training course. By training it on a carefully curated set of your company’s internal data, you’re not just giving it access to facts — you’re teaching it your company’s structure, style, or processes. For example, fine-tuning can help a model understand what your financial reports look like, how your project plans are formatted, how to interpret internal jargon, or even how a specific workflow is typically executed, based on hundreds of screencasts showing employees doing the task.
In practice, fine-tuning is usually done by retraining only the uppermost layers of a pre-trained model, using techniques such as LoRA (Low-Rank Adaptation). This is applied to open-weight models like LLaMA, Mistral, or OpenAI’s gpt-oss (catchy name, right?). Open-weight means the model’s parameters (think billions of numbers) are made publicly available, allowing others to run it on their own infrastructure and adapt it to their needs.
If this sounds like a return to the “old AI paradigm” we discussed at the start of the article - using proprietary data to train a narrow-purpose machine learning model - you’re exactly right. Even though we’ve come a long way from traditional predictive models, the underlying technology is still the same: a neural network. The difference is that now you start with a pre-trained generalist “thinking system”, and with fine-tuning, you can teach it new patterns or overwrite original ones.
Today, fine-tuning is still relatively rare in enterprise use. Most organisations have simpler ways to augment Agentic AI systems with the necessary context and data, as discussed in the previous two sections. However, we view fine-tuning as a growing trend. It requires many of the same components as traditional ML model training: high-quality data in a well-structured, easily accessible format, supported by strong data governance.
FAQ
let's talk about your own AI-enabled product idea!
The form is loading...


