
share this post on


Shaping the future of finance — Part III: Big Data
an explanation for non-technical mortals
27 August, 2019
The future-shaping power of new technologies
In this series of articles, we focus on four key technologies that are changing the face of the financial industry today. In the upcoming weeks, we are going to devote a separate blog post to each of the following topics that we consider the most influential technologies today in financial services.
1. The tech behind Open Banking and PSD2
2. Microservices and Containerization
3. Big Data
4. Artificial Intelligence and Machine Learning
There is no denying that the future in financial services will belong to those who understand the tech behind it. This guide will help you to make sure you have a crystal clear picture. Let’s dig into Big Data now.
3. Big Data
Banks have been gathering a huge amount of data about us in recent years. They know all about where we spend our money and what we spend it on, how much we spend on travel or gambling and how frequently we reach our credit limit. This data usually sits in silos tied to specific services.
Accessing or using the silos to build new services is an enormous amount of work. Also, these older-type services store only the most important data to minimize the amount that needs to be handled. Oftentimes the systems cannot handle more than a few years of it, so older chunks are backed up every now and then, making them entirely inaccessible to other services.
Do you like maple syrup? This is just like making maple syrup. Imagine you own a forest of maples. To make syrup you need to tap the trees. In fact, you need to concentrate on tapping the best trees. Old-style data systems are like the syrup producer who can only access the first few rows of trees. What a loss of potential! What a crime against pancakes!
This is a classic missed opportunity! We cannot build smart, real-time services with inaccessible and incomplete data. What we need is the ability to make predictions based on lots of good data. Who is thinking about getting a loan? Who is apt to buy travel insurance after buying their airplane ticket? With such information at hand we can show customers relevant products and services at the exact moment they need them.
In essence, what our maple syrup producer really needs to do her job is the ability to see all the trees in the woods and to get to any of them (perhaps the best ones) quickly.
These are the kinds of problems where Big Data comes in and makes cutting-edge applications possible.
Data processing pipeline
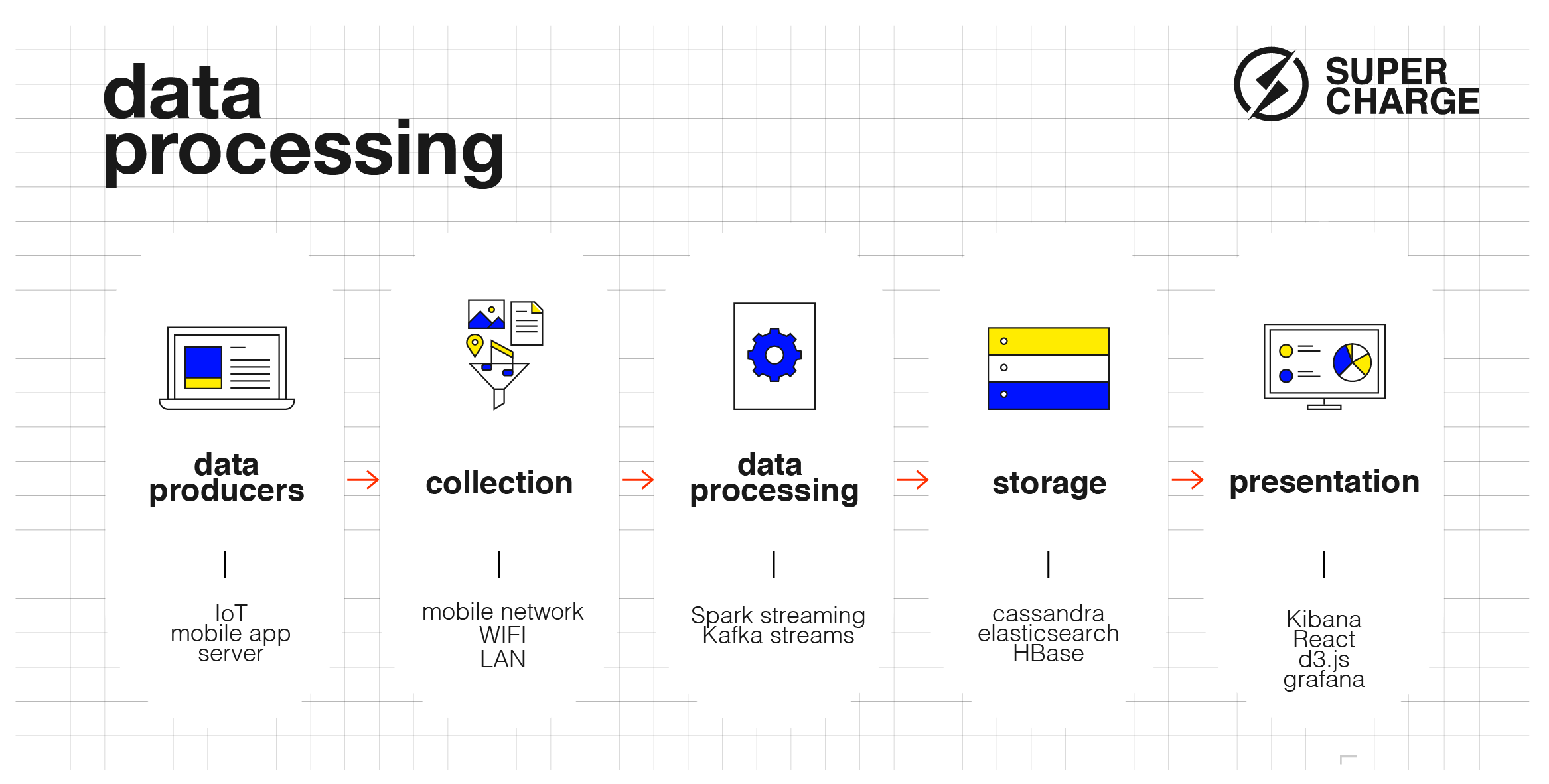
Figure 1: How all that data is processed and the technologies used meanwhile
Big Data solutions aim to capture as much data as possible, enrich it with all possible information (e.g., make connections to already existing data) and store it in a place where it can be easily retrieved, processed and visualized. It can also make sense to save data in its raw native format, creating a data lake.
Let’s go through the steps of how data goes through a system and what technologies we can use along the way. We’ll use open-source Apache technologies for our examples, but there are many alternatives at every step in other data processing ecosystems.
Data producers
This is where data is created. This can entail analytics events from a mobile phone, payment transactions from a POS terminal, an authentication log event from the auth server or literally anything else. When data is created we need to make sure it reaches the processing pipelines so it will be stored somewhere. In the maple syrup industry, the data producers would be the maple trees.
Collection
This is the layer and protocol for how the data gets into the processing pipeline. It usually moves through some kind of network: internet, lan, etc… In IoT use-cases, MQTT is a standard protocol for data transport, while HTTP is another popular protocol for web-based applications. So for our maple syrup producer, this step is the same as tapping the trees and carrying the buckets of sap to the cooking house.
Data processing
There are two main ways we process data. The first is Batch Processing, which means that a certain process reads a large chunk of data, processes it and publishes the results. Then it retrieves the next chunk of data and processes that as well. This is repeated until all the data is processed. Hadoop is one of the most famous batch processing software. It can process huge amounts of data, but not necessarily in real-time. The usual use cases are report generation and analyses of unstructured data.
The second type of processing is called Stream Processing. It processes the data on the go in real-time. Spark streaming or Kafka streams are two regular players here. The usual use cases are data transformation, firing actions on certain events or machine learning model updates. Stream Processing is used when we need immediate actions upon data arrival. What would a maple syrup producer be doing in this stage? Cooking the sap, of course!
Storage
Selecting the right data storage is critical in terms of solutions we can build on top of the data. Every storage solution has advantages and disadvantages specific to certain types of data and certain types of data retrieval mechanisms. We need to select the right storage for the right use case.
Without going into detail, let’s look at a couple of examples: if we want to store large amounts of unstructured data and process them with Hadoop, most probably we should go with HBase as the underlying datastore. If we want to categorize payment transactions for a customer and save it as a database which we can later read in real-time we should use Cassandra. Should we want to search our data with a lot of dimensions we would be wise to use ElasticSearch.
As you can see, there are plenty of possible solutions, so we need to choose wisely. Sometimes it can also make sense to save the same data into multiple databases so we can always query the one that best fits our use case. Of course, these are issues you’ll need to discuss with your data engineers. And if you don’t have a data engineer and you’re sitting on this much data, maybe it’s time to make that call. I mean, could you imagine a maple syrup producer without a warehouse for storing syrup, and without a system to manage all those barrels?
Presentation and visualization
After we’ve processed the data, generated the insights and stored them in a database, we would like to animate it through visualization. There are specialized visualization tools for certain types of data, like Kibana to display logs or Grafana to display time-series data. These tools come with Enterprise-grade features so we don’t need to worry about authorization and security.
Should the above-mentioned tools not be sufficient for our use case we can easily create our own custom visualization tool with web technologies like React or d3.js. In this case, we also need to think about the security aspects of the visualization application. For fans of maple syrup, this step is akin to knowing what you need to know about the warehouse, and to putting fancy labels on elegant jars of your syrup.
Conclusion
This future has arrived. For example, TrueMotion has already started collecting and using driving telemetry data to help reduce the risk for car insurance companies. Seon helps pinpoint fraudulent activities in your data streams to make your system a safer place for your customers.
Utilizing these big data solutions can create immediate business value. Imagine having the ability to capture any event happening in your system and being able to take immediate actions on them. This event stream is set to become the backbone of modern IT infrastructures. To sum it all up, in order to offer the very best services and apps, it is essential we make the most of our data. With its accessibility, speed and comprehensiveness, big data makes sure you are never left in the dark. Or without the best syrup on your pancakes.


