
share this post on


Shaping the future of finance – Part IV: AI and Machine Learning
an explanation for non-technical mortals
05 September, 2019
The future-shaping power of new technologies
In this series of articles, we focus on four key technologies that are changing the face of the financial industry today.
1. The tech behind Open Banking and PSD2
2. Microservices and Containerization
3. Big Data
4. Artificial Intelligence and Machine Learning
There is no denying that the future in financial services will belong to those who understand the tech behind it. This guide will help you to make sure you have a crystal clear picture. In this last article, we will look at how AI and Machine Learning are helping you innovate in the financial sector.
4. Artificial Intelligence and Machine Learning
Like in all areas of life — fintech being no exception — both end-users and service providers show an ever-increasing need to have “intelligent” solutions to practical problems, like how to deal with fraud or mitigate risks of becoming complicit in money-laundering. Intelligence, whether artificial or not, leads to higher efficiency and lower costs, better customer experiences, high levels of compliance and security, and the ability to solve problems quickly.
Most often such problems would be relatively simple for a truly intelligent human to solve, but they pose a much bigger challenge for programs and programmers alike.
Nowadays handling Personal Finance Management (PFM) is a very common use-case for financial institutions. Imagine you bought your shiny new TV at your local Tesco the other day. You expect your banking app to categorize it as a Home Spending, I mean it’s clearly not Groceries, right?
Or let’s take fraud detection as another example. For every $1 lost in fraud, banks pay almost $3 for recovery. The crystal clear goal then is to detect the highest number of frauds without unnecessarily annoying customers with false alarms. Because obviously that credit card charge from last Friday evening in Amalfi is because you took your well-deserved weekend off, and not because someone’s up to no good.
Well, it’s not that clear and not that obvious — at least not from the program’s perspective.
AI Definitions 101
For an outsider, diving into the AI world can be quite confusing. Abstract concepts and two-letter abbreviations abound, so first let’s clarify what we mean when discussing terms like Artificial Intelligence, Machine Learning or Deep Learning.
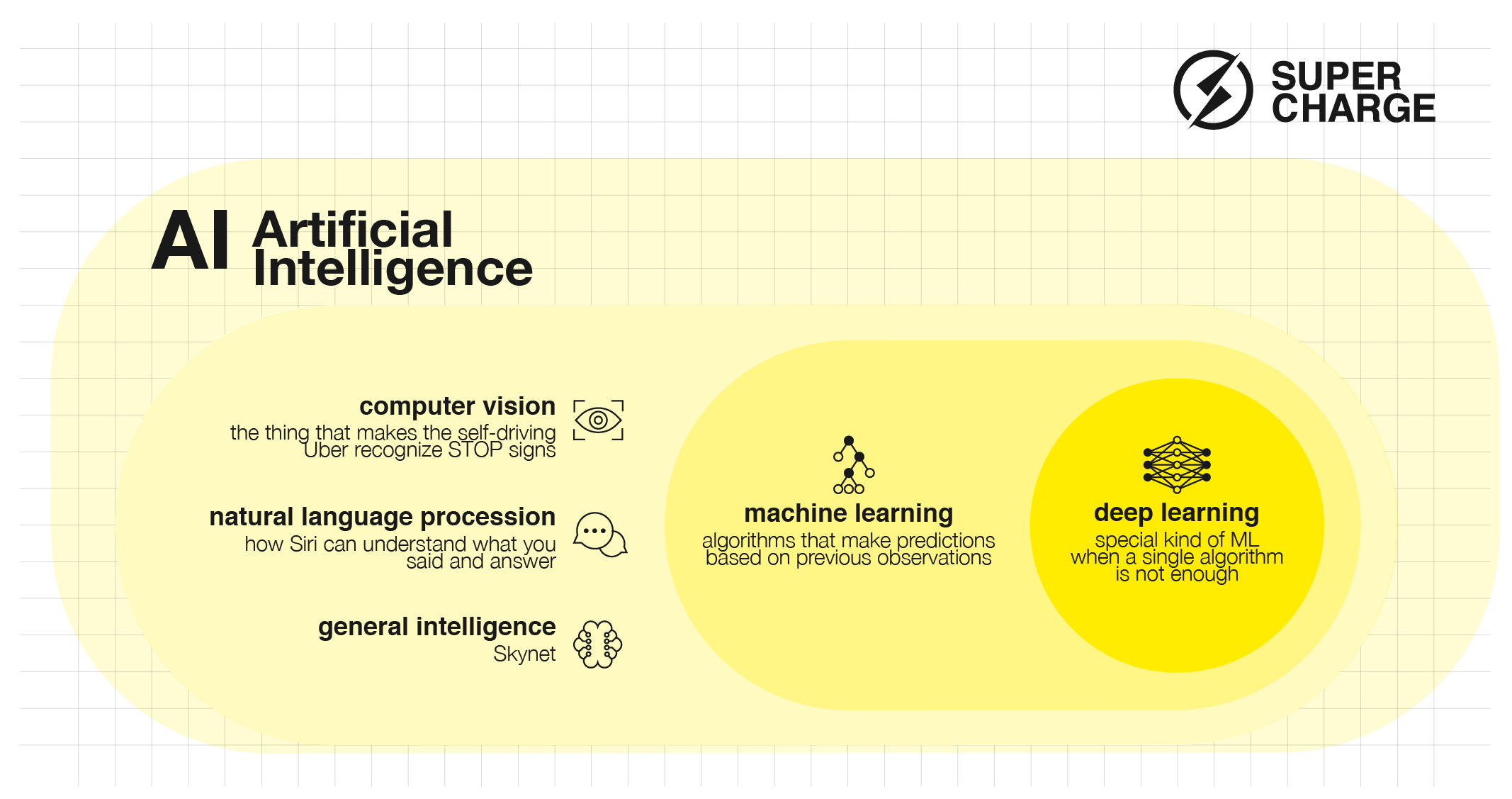
Figure 1: AI 101
Artificial Intelligence is the broadest term which denotes the whole field in computer science which deals with solving problems traditionally associated with intelligent “learning” or “problem solving”.
Under the big umbrella of Artificial Intelligence, Machine Learning is the study of algorithms which (with proper training) can learn to solve new tasks without being explicitly programmed to do so.
The term Deep Learning covers a subset of Machine Learning methods which combine different “standard” ML techniques to effectively adapt to and make decisions from vast amounts of data.
On the same hierarchical level as ML are the subfields of Natural Language Processing or Computer Vision. Although in articles fintech problems are almost exclusively associated with ML, typical fintech use-cases like the automation of Customer Service or introducing Digital Assistants rely heavily on other areas of AI, like NLP.
The duck test for AI
So this new thing my company is so obsessed with is labelled as AI, promoted as AI, and has an AI price tag, but is it really AI?

Figure 2: AI Duck Test — Just as in the case of the proverbial duck, a lot of things can look and behave like an AI — and actually be nothing more then a big pile of “IF this, then that” functions or a human operators in a far off location carefully sorting data to categories
It’s not that easy to tell. Speaking more in layman’s terms: when talking about “AI solutions” experts generally mean some program which is not based on the “if Tesco: then Grocery” scheme, but which is able to get smarter over time and learn from its own mistakes.
Be aware! Having an AI-based solution doesn’t necessarily mean that it would be inherently better than a “traditional” one. In situations where you find it difficult to identify the problem you’re facing, AI is generally a “good fit.” This is one of the reasons many companies find it tough to take the first step toward adopting these new technologies.
Why is it so hard to jump into AI?
First of all, let’s be realistic: for the vast majority of software vendors working with AI/ML technologies is not part of their well-established day-to-day operations. Developing a custom AI solution certainly requires a fair amount of R&D effort. And it’s not just the core algorithmic part that can cause headaches… A custom-built AI project calls for a very diverse skillset: having someone on the team who understands AI is just a small — but inarguably vital — part of the big picture.
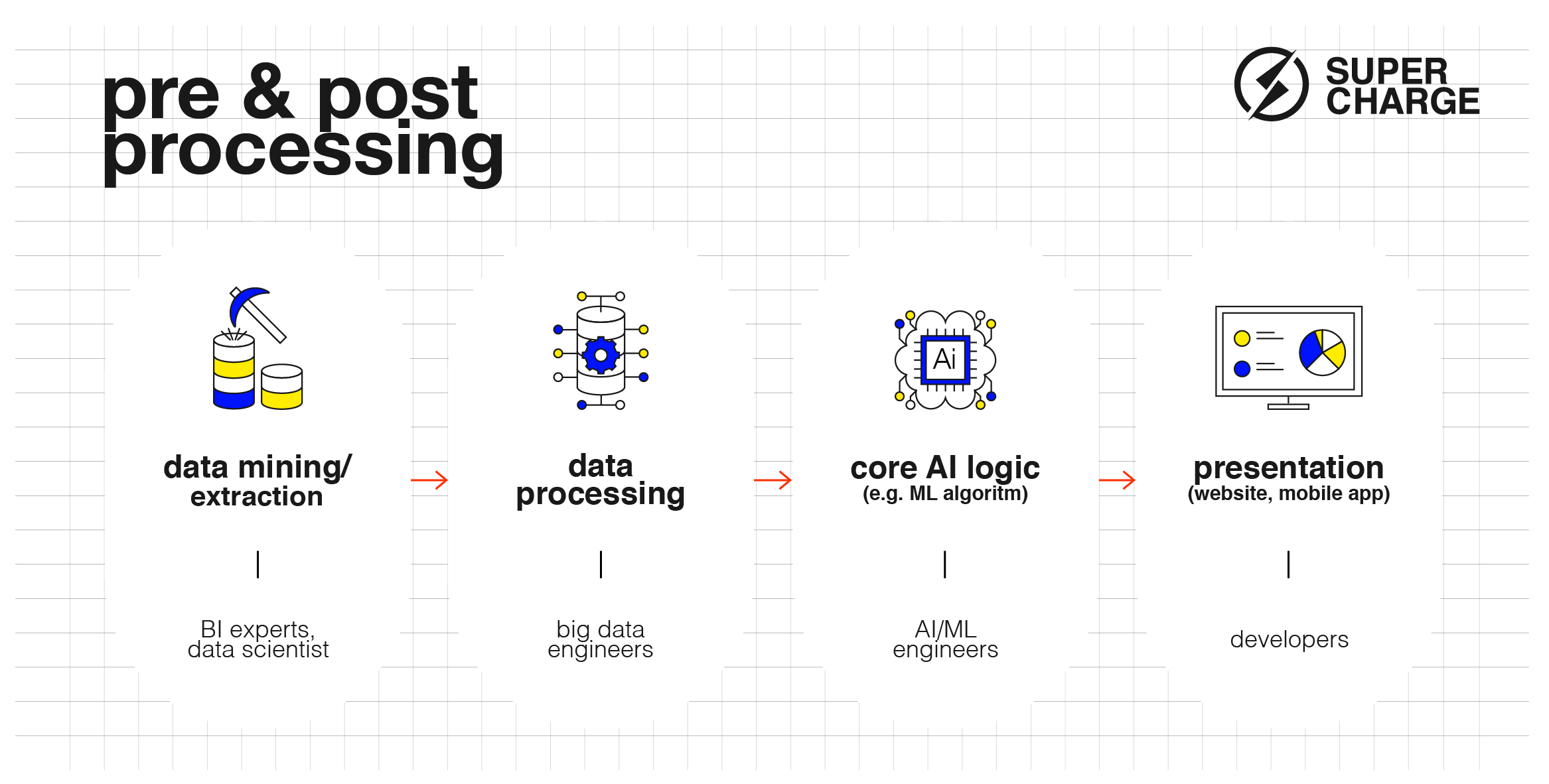
Figure 3: ML Pipeline with pre and post processing steps
A fundamental issue is the importance of data — both in quality and quantity. You can’t train an ML model with thin air! You’ll need data in order to teach your machine. Probably a lot of it.
To be able to train your PFM (Personal Finance Manager) categoriser to identify that “tricky” kind of TV purchase at Tesco you need to have a large number of correctly categorised examples.
And who will categorise those millions of transactions, you ask? Well, that’s the — sometimes literally — million-dollar question. We’ll get back to it later.
In terms of data quantity the deal is fairly simple: the more the better. Keep in mind that no matter how much good quality data you piled up, you can only use about 60% of it for the actual training set. You need to put aside about 20% for a validation set which is used to prevent the algorithm from fitting too much on the training set (the whole point of using an AI-based solution is to be able to solve “unknown” problems, not just the ones you trained for). And finally, how can we objectively determine how good our new ML model is? The remaining ~20% data points are used as a test set — they are evaluated after completing training in order to see how the model would perform “in the wild”, but still in a controlled and measurable environment.
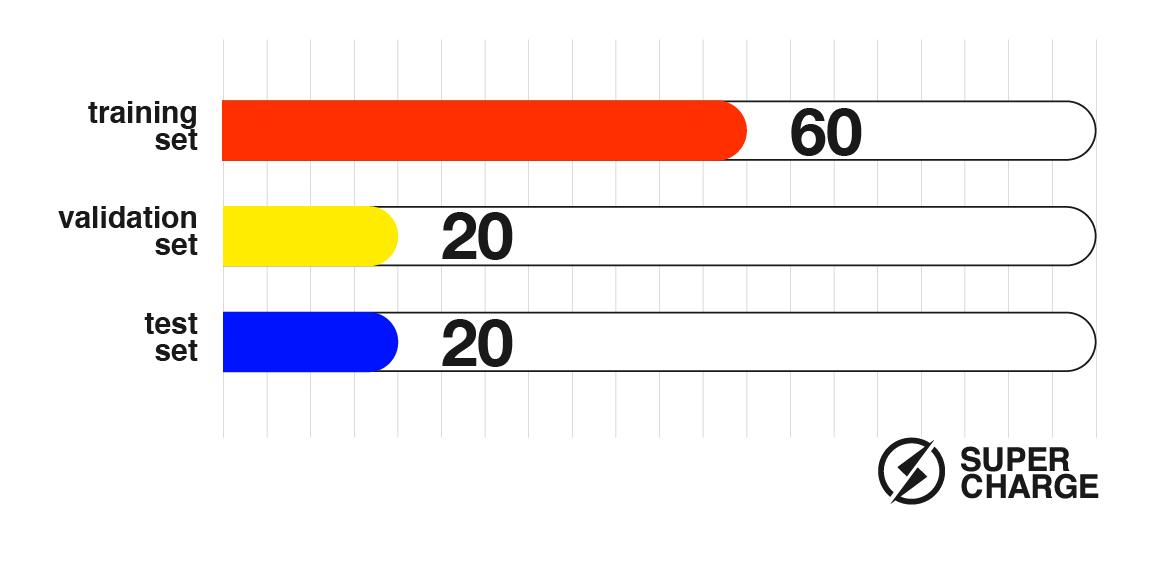
Figure 4: How data is used in an ML pipeline
Another factor that doesn’t seem unique to AI projects is the fact that it’s extremely hard to spot and fix bugs. Isn’t this true for all kinds of software development? Generally, it is, but in a typical ML pipeline, there are so many moving parts which need to be perfectly aligned with each other that the pipeline is particularly sensitive to any small disturbance. When something goes south, what causes it? Is it the data? Is it a simple bug in the preprocessing pipeline? The training parameters? The ML algorithm itself?
Finally, I’d like to mention one more important factor from the business side of things, which is the need for new or updated KPIs that function with the non-deterministic nature of AI solutions. In a fraud detection system, it probably doesn’t make sense to count only on the hard number of actual fraud attempts caught by the system. A good KPI would factor in the additional benefit an intelligent system would bring to the table by reducing the number of false alarms and thus the load on customer support.
On pitfalls and how to avoid them
Let’s do a quick recap of the pitfalls of working on an AI project we collected in the previous sections:
- Possible massive R&D work
- Data, data, data
- Particularly hard to fix bugs
- Need for a new way of thinking about the right KPIs
Undertaking these might cost a lot of time and money. Luckily, we happen to have some pieces of advice to help guide you through the process of kicking off an AI project.
First of all — with the help of domain and AI experts — try to gather as much information as possible to make sure you understand the complexity and extent of the problem. There’s no need to reinvent the wheel. See if your use cases match those that are already implemented by one of the tech giants like Google or Amazon.
Try to use an existing ML model if you can, leveraging the time other companies put into a refined solution. Also, be cautious with random ML models on GitHub implemented by a single developer. The lack of proper testing and validation might cause you more headaches than you save on the implementation costs.
Whether you’re going to use an existing model or create a new one you need to identify the steps of the pipeline you should build, and then assemble a team of experts for each field. Trust me, when implementing all the Big Data preprocessing steps it’s better to start with sanitized and good quality data at your disposal.
Speaking of data, we already covered the fact that you’ll need a lot of it. If you’re sitting on a big pile of good quality data (e.g., a lot of transactions already categorized for a PFM) then you’re in luck. If not, investigate the option to buy data — but be prepared, it can be very pricey. An alternative could be to build a dataset yourself. You can consider using your existing user base to help you build the necessary dataset for you.
(Sidenote: Remember the million-dollar question? You’re already solving it for Google every time you mark images with traffic signs or vehicles in CAPTCHAS.)
In order to minimize the number of bugs and the time spent on finding and fixing them, utilize an iterative approach, especially for the actual ML algorithms. Start with the simplest ML model you can think of to filter out bugs in the pre- or post-processing steps. Only increase complexity when you’re already seeing good results.
And last but not least, on the business side try to set up realistic KPIs and expectations that can take advantage of the AI approach. Even if it feels a bit unnatural at first, try to embrace the potential strengths of the AI-based approach.
For example, when setting KPIs up for your new fraud detection system think of it as someone with actual intelligence. It might make a few errors on even simple tasks, but in the grand scheme of things, you’ll benefit from its ability to deduce hidden logical connections and learn from its mistakes.
There is no denying that AI and ML are coming into the fintech world. Some will be ready for it, others not. By embracing AI, you will be nipping emerging problems and issues in the bud, ultimately raising efficiency and revenue, giving you the edge and more time to watch that new TV of yours.
The most important conversation
We believe that companies that are able to successfully integrate people, tech and business are the ones that will prevail. This can only happen through fruitful conversations between designers, engineers and decision-makers. To start, everyone needs to take time to understand basic concepts and their interconnections in today’s tech landscape. We hope that our article helped you gain some clarity — from infrastructure to smart recommendation engines.


